26 Mar Save Time and Money by using a Generic Load Process to Integrate Non-SAP Master Data in HANA

To meet business reporting requirements, I have often encountered the need to integrate master data with SAP transactional data in the Data Warehouse. Typically, I create a point-to-point interface to meet the requirement. The point-to-point interface entails creating an interface spec, target object spec, drop folder, load template, development, testing, and the required migration paperwork to move the objects through the landscape. Even if the master data is simple, it is costly and time-consuming to develop a reliable load process for the business.
One simple approach to save time and money is to create a generic load process. The process and associated objects can then be re-used for any master data that is needed to support reporting requirements. Figure 1 outlines the process of the template load.
Figure 1: Template Generic Load Process
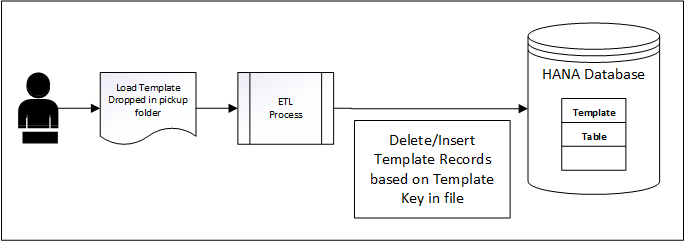
To support a wide variety of master data attributes, the template and target table need to be defined with a mix of data types and include multiple sets of these columns. The only required field in the template is the template key, and there can ONLY be one per file. The load process will delete ALL records in the target table based on the unique template key found in the file submitted. The records in the new file will then be loaded into the table and represent the latest set of data submitted in the file.
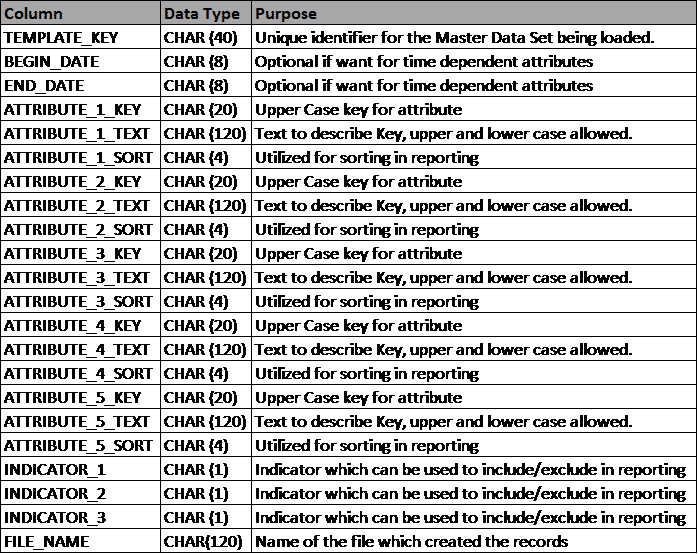
The target table includes a begin and end date column for time-dependent data. In addition, there is key, text, and sort column for each attribute set. The sample table structure in Figure 2 shows five sets of attributes. However, most tables that I create include ten sets to keep it flexible. Set up the table with as many sets required to accommodate the expected needs of the business.
Figure 2: Sample table structure
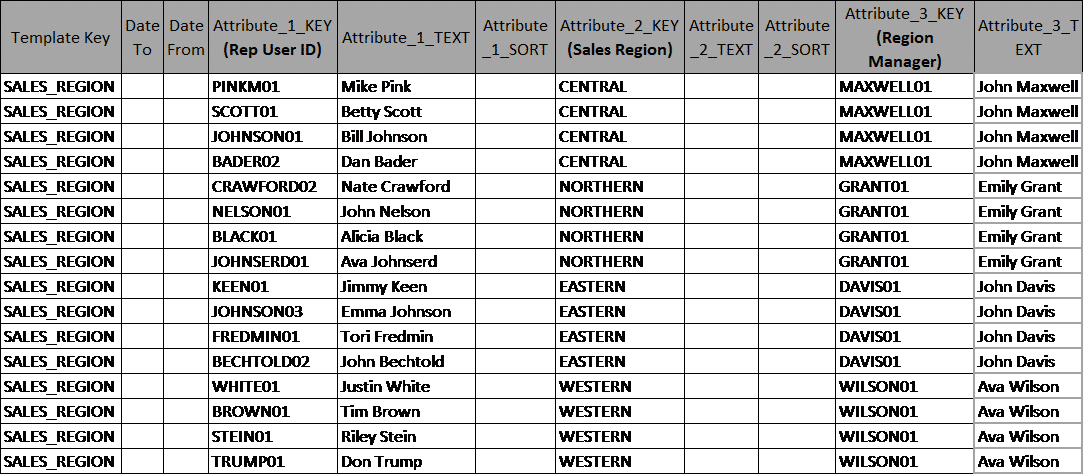
To consume the loaded template data in HANA models you simply just add a filter to the projection in your model based on the template key. One can use the template data in a variety of ways. The most common way is to utilize this information in a dimension model. Then use this dimension model in other models as needed. I have seen it used for data mapping, generic report controls, user message controls, etc. Figure 3 illustrates an example of a Sales Region mapping. Attribute 1 Key captures “Sales Rep User ID”, this represents the “KEY”. This eventually will join sales fact data in HANA models. The Attribute 2 Key column represents the “Sales Region” and Attribute 3 represents the “Region Manager”.
Figure 3: Sample
Although this is actually a fairly simple solution, I have seen it save thousands of dollars and hours for clients. It is not uncommon for clients to have used it to load 30-40 unique templates over time. A generic load process saves money and supports an Agile approach to development once in place.
No Comments